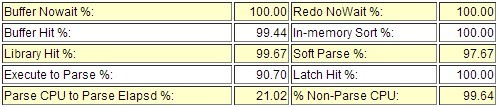
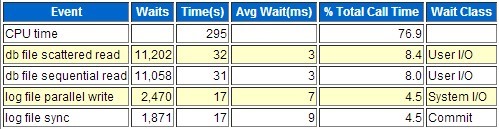
在前一篇中提到一个客户的数据库hung死,但是由于没有数据库hung死时的相关详细信息(除alert.log中),因此在事后定位数据库hung死原因时遇到重重困难,因此该篇贴出MOS上一篇《如何收集数据库hung死时的诊断信息的文章》[How to Collect Diagnostics for Database Hanging Issues (文档 ID 452358.1)],以供参考!
Applies to
Oracle Database – Enterprise Edition – Version 9.0.1.0 and later
Oracle Database – Standard Edition – Version 9.0.1.0 and later
Oracle Database – Personal Edition – Version 9.0.1.0 and later
Information in this document applies to any platform.
Goal
When a database appears to be hung, it is useful to collect information from the database in order to determine the root cause of the hang. The root cause of the hang can often be isolated and solved using the diagnostic information gathered. Alternatively, if this is not possible, we can use the information obtained in order to help eliminate future occurences
Solution
What is needed to diagnose “Database Hang” issues? Database hangs are characterised by a number of processes waiting for some other activities to complete. Typically there is one or more blockers that are stuck or perhaps working hard and not freeing resources quickly enough. In order to diagnose this the following diagnostics are needed:
A. Hanganalyze and Systemstate Dumps
B. AWR/Statspack snapshots of General database performance
C. Up to date RDA
Please refer to the relevant sections below for more details on how to collect these.
A. Hanganalyze and Systemstate Dumps If there are problems making this connection then in 10gR2 and above, the sqlplus “preliminary connection” can be used : Note: From 11.2.0.2 onwards, hanganalyze will not produce output under a sqlplus “preliminary connection” since it requires a process state object and a session state object. If a hanganalyze is attempted, the trace will output: 2-2) Systemstate 3) Collection commands for Hanganalyze and Systemstate: RAC 3-1) Collection commands for Hanganalyze and Systemstate: RAC with fixes for bug 11800959 and bug 11827088 3-2) Collection commands for Hanganalyze and Systemstate: RAC without fixes for Bug 11800959 and Bug 11827088 Explanation of Hanganalyze and Systemstate Levels On RAC Systems, hanganalyze, systemstates and some other RAC information can be collected using the ‘racdiag.sql’ script, see: V$wait_chains
B. Provide AWR/Statspack snapshots of General database performance
C. Gather an up to date RDA
Proactive Methods to gather information on a Hanging System Additionally, this script can collect information with lower impact on the target database. 3) Procwatcher 4) OS Watcher Black Box OSWatcher Black Box contains a built in analyzer that allows the data that has been collected to be automatically analyzed, pro-actively looking for cpu, memory, io and network issues. It is recommended that all users install and run OSWbb since it is invaluable for looking at issues on the OS and has very little overhead. It can also be extremely useful for looking at OS performance degradation that may be seen when a hang situation occurs.
Oracle Enterprise Manager 12c Real-Time ADDM
Retroactive Information Collection 4) Alert log and any traces created at time of hang
PS: This article comes from MOS…
Hanganalyze and Systemstate dumps provide information on the processes in the database at a specific point in time. Hanganalyze provides information on all processes involved in the hang chain, whereas systemstate provides information on all processes in the database. When looking at a potential hang situation, you need to determine whether a process is stuck or moving slowly. By collecting these dumps at 2 consecutive intervals this can be established. If a process is stuck, these traces also provide the information to start further diagnosis and possibly help to provide the solution.
a) Hanganalyze is a summary and will confirm if the db is really hung or just slow and provides a consistent snapshot.
b) Systemstate dump shows what each process on the database is doing
Collecting Hanganalyze and Systemstate Dumps steps:
1) Logging in to the system
Using SQL*Plus connect as SYSDBA using the following command:
sqlplus '/ as sysdba'
sqlplus -prelim '/ as sysdba'
HANG ANALYSIS
ERROR: Can not perform hang analysis dump without a process state object and a session state object.
( process=(nil), sess=(nil) )
2) Collection commands for Hanganalyze and Systemstate: Non-RAC
Sometimes, database may actually just be very slow and not actually hanging. It is therefore recommended, where possible to get 2 hanganalyze and 2 systemstate dumps in order to determine whether processes are moving at all or whether they are “frozen”.
2-1) Hanganalyze
sqlplus '/ as sysdba'
oradebug setmypid
oradebug unlimit
oradebug hanganalyze 3
-- Wait one minute before getting the second hanganalyze
oradebug hanganalyze 3
oradebug tracefile_name
exit
sqlplus '/ as sysdba'
oradebug setmypid
oradebug unlimit
oradebug dump systemstate 266
oradebug dump systemstate 266
oradebug tracefile_name
exit
There are 2 bugs affecting RAC that without the relevant patches being applied on your system, make using level 266 or 267 very costly. Therefore without these fixes in place it highly unadvisable to use these level.
For information on these patches see:
Document 11800959.8 Bug 11800959 - A SYSTEMSTATE dump with level >= 10 in RAC dumps huge BUSY GLOBAL CACHE ELEMENTS - can hang/crash instances
Document 11827088.8 Bug 11827088 - Latch 'gc element' contention, LMHB terminates the instance
sqlplus '/ as sysdba'
oradebug setorapname reco
oradebug unlimit
oradebug -g all hanganalyze 3
oradebug -g all hanganalyze 3
oradebug -g all dump systemstate 266
oradebug -g all dump systemstate 266
exit
sqlplus '/ as sysdba'
oradebug setorapname reco
oradebug unlimit
oradebug -g all hanganalyze 3
oradebug -g all hanganalyze 3
oradebug -g all dump systemstate 258
oradebug -g all dump systemstate 258
exit
Note: In RAC environment, a dump will be created for all RAC instances in the DIAG trace file for each instance.
Hanganalyze levels:
1)Level 3: In 11g onwards, level 3 also collects a short stack for relevant processes in hang chain
Systemstate levels:
2)Level 258 is a fast alternative but we’d lose some lock element data
3)Level 267 can be used if additional buffer cache / lock element data is needed with an understanding of the cost
Other Methods
If connection to the system is not possible in any form, then please refer to the following article which describes how to collect systemstates in that situation:
Document 121779.1 Taking a SYSTEMSTATE dump when you cannot CONNECT to Oracle.
Document 135714.1 Script to Collect RAC Diagnostic Information (racdiag.sql)
Starting from 11g release 1, the dia0 background processes starts collecting hanganalyze information and stores this in memory in the “hang analysis cache”. It does this every 3 seconds for local hanganalyze information and every 10 seconds for global (RAC) hanganalyze information. This information can provide a quick view of hang chains occurring at the time of a hang being experienced.
For more information see:
Document 1428210.1 Troubleshooting Database Contention With V$Wait_Chains
Hangs are a visible effect of a number of potential causes, this can range from a single process issue to something brought on by a global problem.
Collecting information about the general performance of the database in the build up to, during and after the problem is of primary importance since these snapshots can help to determine the nature of the load on the database at these times and can provide vital diagnostic information. This may prove invaluable in identifying the area of the problem and ultimately resolving the issue.
To do this, please take and upload snapshot reports of database performance (AWR (or statspack) reports) immediately before, during and after the hang..
Please refer to the following article for details of what to collect:
Document 781198.1 Diagnostics for Database Performance Issues
An up to date current RDA provides a lot of additional information about the configuration of the database and performance metrics and can be examined to spot background issues that may impact performance.
See the following note on My Oracle Support:
Document 314422.1 Remote Diagnostic Agent (RDA) 4 - Getting Started
On some systems a hang can occur when the DBA is not available to run diagnostics or at times it may be too late to collect the relevant diagnostics. In these cases, the following methods may be used to gather diagnostics:
1) As an alternative to the manual collection method notes above, it is also possible to use the HANGFG script as described in the following note to collect the information:
Document 362094.1 HANGFG User Guide
2) LTOM
The Lite Onboard Monitor (LTOM) is a java program designed as a real-time diagnostic platform for deployment to a customer site.LTOM proactively provides real-time automatic problem detection and data collection.
For more information see:
Document 352363.1 LTOM - The On-Board Monitor User Guide
Procwatcher is a tool that examines and monitors Oracle database and/or clusterware processes at a specific interval. The following notes explain how to use Procwatcher:
Document 459694.1 Procwatcher: Script to Monitor and Examine Oracle DB and Clusterware Processes
Document 1352623.1 How To Troubleshoot Database Contention With Procwatcher
Refer to the following for download, user guide and usage videos on OSWatcher Black Box:
Document 301137.1 OSWatcher Black Box User Guide (Includes: [Video])
Real-Time ADDM is a feature of Oracle Enterprise Manager Cloud Control 12c that allows you to analyze database performance automatically when you cannot logon to the database because it is hung or performing very slowly due to a performance issue. It analyzes current performance when database is hanging or running slow and reports sources of severe contention.
For more information see the following video: Oracle Enterprise Manager 12c Real-Time ADDM
Sometimes we may only notice a hang after it has occurred. In this case the following information may help with Root Cause Analysis:
1) A series of AWR/Statspack reports leading up to and during the hang
2) ASH reports – one can obtain more granular reports during the time of the hang – even up to one minute in time.
3) Raw ASH information. This can be obtained by issuing an ashdump trac. See:
Document 243132.1 10g and above Active Session History (Ash) And Analysis Of Ash Online And Offline
Document 555303.1 ashdump* scripts and post-load processing of MMNL traces
On a RAC specifically check the following traces files as well: dia0, lmhb, diag and lmd0 traces
5) RDA as above